

 ▲ 图片由AI生成
▲ 图片由AI生成
每日科技头条讯:LLM强势挺进端侧,AI大语言模型端侧部署如何影响超自动化?
端侧部署对大语言模型落地有什么好处?对超自动化有什么影响?
产业上下游齐发力LLM挺进端侧,大语言模型加速落地利好超自动化
芯片、云服务、终端厂商齐发力,LLM决胜端侧,超自动化受益其中
从谷歌推出Gecko到高通引入Llama 2,端侧部署成为LLM落地重要方向
大语言模型端侧部署+LLM超自动化,“贾维斯”智能管家照进现实
文/王吉伟
算力资源吃紧,成本居高不下,数据隐私泄露,用户体验不佳……
以OpenAI为代表的大语言模型爆发后,多重因素影响之下本地化部署成为LLM落地的主流模式。LLM迫切需要部署在本地设备上,围绕LLM端侧部署的研究与探索空前高涨。
5月份,Google推出了可以在旗舰手机上离线运行的PaLM2 轻量版Gecko。
从这一刻起,能够在端侧运行的大语言模型成了厂商们的重要任务。毕竟LLM要落地,移动终端是最好的载体之一,同时端侧也有着巨大的市场空间。
于是,厂商们纷纷开启狂飙模式,踏上LLM的压缩、蒸馏及优化之路,要把自家的云端大模型先行装进手机。
也就是在此期间,高通提出了混合AI概念:AI处理必须分布在云端和终端进行,才能实现AI的规模化扩展并发挥其最大潜能。

端侧的市场规模,加上混合AI趋势,就连微软也与Meta结盟共同推出了可以部署在端侧的开源大语言模型Llama 2。
被称为“GPT-4最强平替”的Llama 2,可以让开发者以很低的成本为客户提供自主大模型,将为开发者们带来更多可能性和创新机遇。
由此开始,各家芯片厂商全力研发能够适配各种大模型的芯片、技术以及解决方案。
虽然能够支持LLM本地运行的芯片还没有量产,但高通在世界人工智能大会期间于手机端使用SD十几秒生成一张图片的演示,迅速吸引多方眼球。
高通计划2024年开始在搭载骁龙平台的终端上支持基于Llama 2的AI部署,联发将在下半年发布的下一代旗舰SoC也将支持AI部署。

端侧部署芯片蓄势待发,智能终端厂商披星戴月。
尤其是手机厂商,都在全力进行面向LLM的研发与测试,目前基本都已发布基于云端的自有大语言模型,更想全力争夺LLM端侧部署的先发时刻。
产业链上下游雨点般的密集动作,彰显LLM正在快速挺进端侧。
关注王吉伟频道的朋友知道,LLM也正在与超自动化高速融合,并为超自动带来了从技术架构到产品生态再到经营模式的转变。
过去的LLM都在云端部署,就已为超自动化带来了这么大变化。现在LLM即将实现端侧部署,又将为超自动化带来哪些影响?
本文,王吉伟频道就跟大家聊聊这些。
手机厂商推出大模型
7月下旬,外媒爆料苹果公司正在悄悄开发人工智能工具,且已建立了自己的框架“Ajax”来创建大型语言模型。以“Ajax”为基础,苹果还创建了一项聊天机器人服务,内部一些工程师将其称为“Apple GPT”。
一个月后,苹果开始全面招聘工程师和研究人员以压缩LLM,使其能在iPhone和iPad上高效运行。这一举措标志着苹果公司正积极推动人工智能的发展,并希望成为首批开发出能在手机和设备上而非云端有效运行的人工智能软件的公司之一。
8月初,华为在HDC 2023 开发者大会上表示手机小艺语音助手已升级支持大语言模型,可以像目前火热的 AI 聊天机器人那样辅助办公和学习。
同时华为在发布HarmonyOS 4时,也宣布已将AI大模型能力内置在了系统底层。HarmonyOS 4由华为盘古大模型提供底层支持,希望给用户带来智慧终端交互、高阶生产力效率、个性化服务的全新AI体验变革。

小米公司此前并未“官宣”进入LLM赛道,但其大语言大模型MiLM-6B已经悄然现身 C-Eval、CMMLU 大模型评测榜单。截至当前,小米大模型在C-Eval总榜单排名第10、同参数量级排名第1。
在8月14日晚举办的小米年度演讲中,雷军表示小米AI大模型最新一个13亿参数大模型已经成功在手机本地跑通,部分场景可以媲美60亿参数模型在云端运行结果。小米旗下人工智能助手小爱同学已开始升级AI大模型能力,在发布会当天开启邀请测试。
OPPO已在8月13日宣布,基于AndesGPT打造的全新小布助手即将开启大型体验活动。升级后的小布助手将具备AI大模型能力,拥有更强的语义理解对话能力,可以根据需求的文案撰写用户需要的内容,归纳总结等AI能力也将大大增强。

AndesGPT是OPPO 安第斯智能云团队打造的基于混合云架构的生成式大语言模型。该团队在两年前开始对预训练语言模型进行探索和落地应用,自研了一亿、三亿和十亿参数量的大模型OBERT。OBERT曾一度跃居中文语言理解测评基准CLUE1.1总榜第五名,大规模知识图谱问答KgCLUE1.0排行榜第一名。
vivo也在今年5月研发了面向自然语言理解任务的文本预训练模型3MP-Text,曾一举夺得 CLUE 榜单(中文语言理解基准测评)1亿参数模型效果排名第一。有消息透露,vivo将在今年10月左右推出新的OriginOS 4.0系统,新系统将内置AI大模型。
荣耀是最早布局AI的手机厂商之一,其AI能力的进阶主要分为三个阶段:第一阶段是从0到1提出概念,将需求场景化,比如相机可以直接识别绿植、天空,AI能够对图像进行对应的优化;第二阶段,AI有了上下文理解与学习,基于位置、时间对消费者习惯进行整合式机器的决策;第三阶段就是把AI引入端侧。
荣耀也曾公开对外表示,将率先将 AI 大模型引入端侧。
芯片厂商的LLM动作
高通是LLM端侧部署的坚定推动者。
6月初,高通发布了《混合AI是AI的未来》白皮书。高通认为,随着生成式 AI正以前所未有的速度发展以及计算需求的日益增长,AI 处理必须分布在云端和终端进行,才能实现AI 的规模化扩展并发挥其最大潜能。
云端和边缘终端如智能手机、汽车、个人电脑和物联网终端协同工作,能够实现更强大、更高效且高度优化的 AI,混合AI将支持生成式AI应用开发者和提供商利用边缘侧终端的计算能力降低成本,因此混合AI才是AI的未来。(后台发消息 混合 ,获取该白皮书)。
在今年的世界人工智能大会上,高通展示了在终端侧运行生成式AI模型Stable Diffusion的技术演示,和终端侧语言-视觉模型(LVM)ControlNet的运行演示,参数量达到10亿-15亿,能够在十几秒内完成一系列推理。
7月19日,Meta宣布与微软合作共同推出开源大语言模型Llama 2之后,高通随即官宣了与Meta公司的合作,将实现在高通骁龙芯片上可以不联网的情况下,运行基于Llama 2模型的应用和服务。
双方通过合作,可以在智能手机、PC、AR / VR 头显设备、汽车等设备上,运行Llama 2为代表的生成式 AI 模型,帮助开发者减少云端运行成本,为用户提供私密、更可靠和个性化的体验。
高通计划从2024年起,在搭载骁龙平台的终端上支持基于Llama 2的AI部署。目前,开发者已经可以开始使用高通AI软件栈面向终端侧AI进行应用优化。
联发科在4月28日官宣发布了全球首个繁体中文AI大型语言模型BLOOM-zh,该模型于2月份开始内测,至发布时在大多数繁体中文基准测试中优于其前身,同时保持其英语能力。
与高通一样,联发科也在积极拥抱Llama 2。
8月24日,联发科宣布将运用Meta最新一代大型语言模型Llama2以及联发科最先进的人工智能处理单元(APU)和完整的AI开发平台(NeuroPilot),建立完整的终端运算生态系统,加速智能手机、汽车、智慧家庭、物联网等终端装置上的AI应用开发。

预计运用Llama 2模型开发的AI应用,将在年底最新旗舰产品上亮相。
联发科透露,其下一代旗舰SoC天机9300将于下半年推出,常规的性能提升之外,还将整合最新的APU,在手机等终端设备上带来更强的AI能力,类似ChatGPT的服务体验。
6月上旬,也有消息透露三星电子已在开发自己的大型语言模型(LLM)以供内部使用。
除了手机等端侧设备,PC仍旧是重要的个人与企业生产力工具,英特尔也在不遗余力的对大语言模型进行支持。
英特尔在6月份官宣了用Aurora超级计算机开发的生成式AI模型Aurora genAI,参数量将多达1万亿”。
英特尔提供了一系列AI解决方案,为AI社区开发和运行Llama 2等模型提供了极具竞争力和极具吸引力的选择。丰富的AI硬件产品组合与优化开放的软件相结合,为用户应对算力挑战提供了可行的方案。

英特尔还通过软件生态的构建和模型优化,进一步推动新兴的生成式AI场景在个人电脑的落地,广泛覆盖轻薄本、全能本、游戏本等。目前,英特尔正与PC产业众多合作伙伴通力合作,致力于让广大用户在日常生活和工作中,通过AI的辅助来提高效率,带来革新性的PC体验。
AMD在6月中旬发布了最新款数据中心GPU——MI300X,但似乎并不被市场看好,大客户并不买单。
倒是近期陈天奇TVM团队出品的优化算法,实现在最新Llama2 7B 和13B模型中,用一块 AMD Radeon RX 7900 XTX 速度可以达到英伟达 RTX 4090的80%,或是3090Ti的94%。
这个优化算法,让更多人开始关注AMD的GPU显卡,也让更多AMD个人玩家看到了用AMD芯片训练LLM的希望。目前,已经有一些开源LLM模型能够支持A卡。

众所周知,目前英伟达GPU是全球算力的主要构建者。当前想要玩转大语言模型,从B端到C端都离不开英伟达,相关数据预测英伟达将占据AI芯片市场至少90%的市场份额。
Jon Peddie Research(JPR)最新GPU市场数据统计报告显示,2023年第一季度桌面独立显卡的销量约为630万块,英伟达以84%的市场份额继续占据主导地位,大约销售了529万张桌面独立显卡;AMD以12%的市场份额排在第二,出货量大概为76万张。
作为当前最大的算力供应商,英伟达在大语言模型以及生成式AI方面以及发布了很多战略、解决方案及产品。
限于篇幅关于英伟达这里不做赘述,大家可以自行搜索了解。
LLM端侧部署有什么好处?
从芯片厂商到终端厂商,都在抢滩登陆部署大语言模型。现在,他们又将目光聚焦到了LLM的端侧部署,这其中的逻辑是什么呢?
在讨论这个问题之前,不妨先看看端侧部署LLM有哪些好处。
近几年LLM取得了长足的进展,却面临着一些挑战,比如计算资源限制、数据隐私保护以及模型的可解释性等问题,都是制约LLM走进千行百业的重要因素。

LLM端侧部署是指将大语言模型运行在用户的智能设备上,相对于LLM运行云端服务器上,在端侧运行LLM有以下几个好处:
首先,提高用户体验。可以大幅减少网络延迟,提高响应速度,节省流量和电量。这对于一些实时性要求高的应用场景比如语音识别、机器翻译、智能对话等,是非常重要的。
其次,保障数据安全。能够有效避免用户的数据被上传到云端,从而降低数据泄露的风险,增强用户的信任和满意度。对于健康咨询,法律咨询,个人助理等涉及敏感信息的应用场景,非常必要。
第三,增加模型灵活性。在端侧部署LLM可以让用户根据自己的需求和喜好,定制和调整模型的参数和功能。这对于一些需要个性化和多样化的应用场景,有益于内容创作、教育辅导、娱乐游戏等场景的业务与工作开展。
AI 部署本地化具有必要性,优势包括更低的延迟、更小的带宽、提高数据安全、保护数据隐私、高可靠性等。完整的大模型仅参数权重就能占满一张80G的GPU,但是通过量化、知识蒸馏、剪枝等优化,大模型可以在手机本地实现推理。
高通在其AI白皮书《混合AI是AI的未来》中已经预测了LLM的未来发展方向,大语言模型挺进端侧已是大势所趋。包括手机厂商等在内的终端厂商对此需求巨大,产业链上游的芯片厂商自然要不遗余力地基于大语言模型做各种探索。
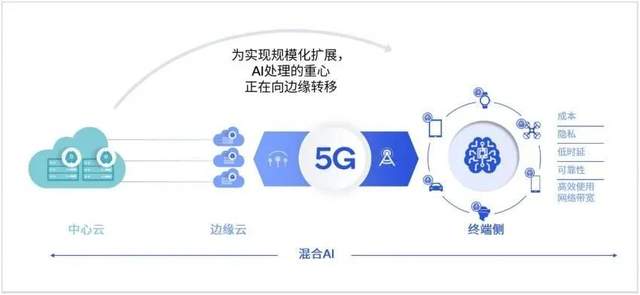
虽然高通、联发科、Intel等芯片厂商已经与Metad Llama 2展开合作,但距离支持LLM端侧运行的移动端芯片还没有规模化量产还有一段时间。
混合AI的趋势下,LLM的本地化与网络化运行都是必需。因此在当前这个空档期,广大终端厂商正在通过云端将大语言模型能力融合到语音助手输入法等工具软件上,以此让用户先行体验生成式AI带来的诸多好处。
云端配合端侧双管齐下部署LLM,以本地终端算力支持大部分生成式AI应用,必要时联动云端算力解决复杂应用问题,在将手机体验提升一大截的同时,也能将算力成本降低更多。
由此,先由云端LLM提升用户体验,后面再通过端侧部署LLM加强体验,将会持续为用户带来更多的惊喜。
如果LLM能够在手机端部署,自然也能在其他终端上部署。
这意味着,在手机之外,包括笔记本电脑、智能家居、VR(Visual Reality,虚拟现实)/AR(Augmented Reality,增强现实)设备、汽车和其他物联网终端,未来都会搭载能够支持LLM的芯片,AIOT将会迎来AIOT大换血,可以想象这是一个多大量级的市场。
而这些产品,几乎所有手机厂商都在做。

此外,手机端运行LLM对硬件有一定的需求,CPU主频越高算力也就越大。
IDC数据显示,2023年一季度全球手机销量中主处理器频率超过2.8GHz 的占比36%,价格在1000 美金以上的占比13%,即旗舰机型占比较低。随着LLM在手机端落地,加上厂商们的大语言模型、生成式AI等的噱头营销,有望推动新一轮换机潮。
面向未来数十亿美元的市场规模,所有智能终端厂商都将受益其中。
这对于从2019年就开始持续下行并且用户换机周期延长的手机市场来说,着实是一场及时雨。而贴上AIGC标签的终端产品,也有望带领消费电子产业走出长期的低迷而进入一个新的经济周期。
端侧部署对超自动化有什么影响
超自动化是一个以交付工作为目的的集合体,是RPA、流程挖掘、智能业务流程管理等多种技术能力与软件工具的组合,也是智能流程自动化、集成自动化等概念的进一步延伸。
超自动化本身涉及到的关键步骤即发现、分析、设计、自动化、测量、监视和重新评估等均囊括在内,突出以人为中心,实现人、应用、服务之间的关联、组合以及协调的重要性。
自生成式AI爆发以后,超自动化领域所辖的RPA、低/无代码、流程挖掘、BPM、iPaaS等技术所涉及的厂商都在积极探索LLM自身的融合应用,目前基本都已通过引入LLM以及基于开源技术研发了自有领域模型。
这些大模型正在与各种产品进行深度交融,进而变革产品形态与创新商业模式。

超自动化是LLM落地的一个重要方向,毕竟自动化是企业优先考虑的增效降本工具及技术。尤其是端到端流程自动化,已是广大组织进行数字化转型的主要途径。
引入生成式AI以后,超自动化将从内容生成自动化和业务流程自动化两个方面同时赋能组织的长效运营。生成式AI将会进一步提升组织的业务流程自动化效率,进而实现更彻底的降本、提质与增效。
LLM对超自动化的影响,可以简单概括为提高效率和质量、增强智能和灵活性、支持决策自动化、拓展领域和范围、增加创新和价值等几个方面。
之前王吉伟频道与大家讨论的LLM与超自动化融合,更多的集中于两者在技术架构融合后所造就的新产品、模式如何提升生产力及创造更多商业价值,没有在LLM部署方面做更多探讨,这里我们可以简单聊一聊这个话题。
大语言模型实现端侧部署,相较于部署在云端的LLM,必然会让超自动化的实施与运行达到更好的效果。

RPA作为企业管理软件,因为一些客户的私有化需求,很多时候都要将RPA部署在本地机房或者私有云环境。在大语言模型的引入上,一些对数据隐私要求比较高的客户只能选择本地化部署LLM,但部署在本地算力成本就成了首要问题。
将来LLM能够部署在端侧,这些客户在算力资源上就获得很大的释放,PC端以及移动端都能够承担一部分算力,可以极大降低算力成本。
因此LLM运行在用户的设备上,可以有效降低超自动化运行的网络延迟,减少云端计算资源的消耗。
在成效方面,LLM的端侧部署可以使超自动化更加灵活和可定制,用户能够根据需求和场景选择合适的AI模型,并且可以随时更新和调整模型。端侧部署也可以使超自动化更加安全和可靠,毕竟用户的数据不需要上传到云端,从而避免了数据泄露或被篡改的风险。

当然,LLM端侧部署也面临一些挑战,比如计算需求量大、对实时性要求高,受限于运行环境、内存、存储空间等,这些正是LLM网络侧部署要解决的问题。
由此,高通所倡导的多种部署方式相结合的混合AI就派上了大用场,这也是LLM的端侧部署为何会成为当前大热门的主要原因。
后记:LLM端侧部署+超自动化将“贾维斯”照进现实
LLM在端侧运行,可以让手机等终端设备在不联网的情况下与用户进行更好的交互,并联动其他移动端比如各种智能家居,以更好的服务用户。
超自动化产品架构中早已引入了对话机器人(Chatbot),目的是通过语音口令自动创建业务流程。但之前的机器人反应不够灵敏,无法与人更好的交互,也无法全面调动RPA进行流程创建,且只能构建或者执行简单的预制业务流程。
将LLM构建于手机等移动终端,基于大语言模型生成能力、语义理解能力和逻辑推理能力,用户就可以通过多轮对话进行业务流程的实时创建,进而构建更多复杂的业务流程,以更智能地处理多项业务。

这意味着,通过手机等终端以语音对话的方式构建并执行工作、生活及学习中的各项业务流程已经成为可能,通过终端调用所在场景中的所有智能终端为个体服务也将成为现实。
目前市面已经出现了类似的产品,比如实在智能的TARS-RPA-Agent模式CahtRPA,就已经做到通过对话实现如生成文本一样流畅地生成并执行业务流程。接下来,将会有更多类似产品出现,这将极大地丰富各领域多场景的超自动化应用。
说到这里,大家脑海中是不是已经有一个机器人管家的形象了?
没错,以大语言模型为核心,以语言为接口,控制多AI模型系统,构建《钢铁侠》中“贾维斯”式的综合智能管家,可以说是每个人的梦想。
而现在来看,将大语言模型进一步构建于端侧,云端与端侧双管齐下,再加上能够生成各种复杂流程的超自动化,使得这个梦想已然照进现实。
 微信扫一扫打赏
微信扫一扫打赏 支付宝扫一扫打赏
支付宝扫一扫打赏




发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。